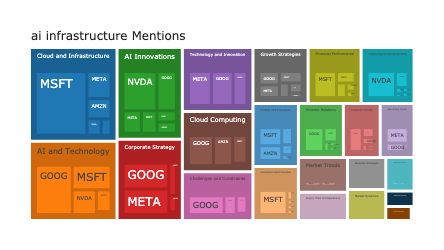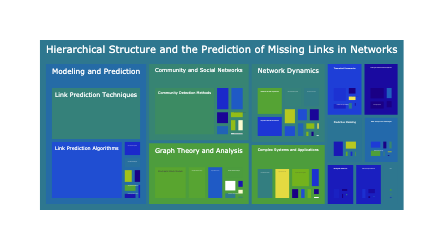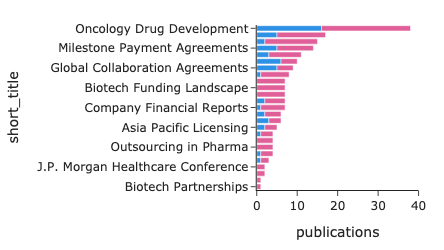
Changes in Novartis’ News Coverage
3 min
from sturdystats import Index
from plotly import express as px
index = Index(id="index_f2ffe2f7901845c59c15aab45685fa3c")## Plotting Settings
import copy
from plotly import io as pio
from plotly import express as px
px.defaults.template = "simple_white" # Change the template
px.defaults.color_discrete_sequence = px.colors.qualitative.Dark24 # Change color sequence
pio.templates["no_margins"] = copy.deepcopy(pio.templates["simple_white"])
pio.templates["no_margins"].layout.margin = {"l": 0, "r": 0, "t": 30, "b": 0, "pad": 0}
pio.templates["no_margins"].layout.plot_bgcolor = 'rgba(0,0,0,0)'
pio.templates["no_margins"].layout.paper_bgcolor = 'rgba(0,0,0,0)'
def procFig(fig):
fig.update_layout(
font_family="Charter",
autosize=True,
plot_bgcolor= "rgba(0, 0, 0, 0)",
paper_bgcolor= "rgba(0, 0, 0, 0)",
margin=dict(
l=0,
r=0,
b=0,
t=30,
pad=0
),
coloraxis_colorbar=dict(
orientation='h', # horizontal orientation
yanchor='top',
y=-0.1, # position below the plot (negative values go below)
xanchor='center',
x=0.5, # center horizontally
thickness=15, # height of the colorbar
len=0.75 # length as fraction of plot width
)
)
fig.layout.xaxis.fixedrange = True
fig.layout.yaxis.fixedrange = True
return fig
pio.templates.default = "no_margins"topic_df = index.topicSearch(limit=500)
topic_df.head(5)| short_title | topic_id | mentions | prevalence | topic_group_id | topic_group_short_title | conc | entropy | |
|---|---|---|---|---|---|---|---|---|
| 0 | Personal Projects | 60 | 20745.0 | 0.101177 | 3 | Projects and Personal Development | 90.538170 | 6.966460 |
| 1 | Open-Source Hosting | 145 | 16622.0 | 0.039764 | 5 | Cloud and Infrastructure | 18.127928 | 6.122626 |
| 2 | Scripting and Automation | 104 | 13892.0 | 0.038917 | 6 | Tools and Utilities | 17.364424 | 5.922157 |
| 3 | Web Development Tools | 141 | 11666.0 | 0.027827 | 0 | Web and Software Development | 18.536110 | 5.498559 |
| 4 | Social Photo Sharing | 135 | 10991.0 | 0.026396 | 4 | Interactive Media and Games | 18.562660 | 5.140318 |
topic_df["title"] = "Show HN"
fig = px.sunburst(
topic_df,
path=["title", "topic_group_short_title", "short_title"],
values="prevalence",
height=500
)
fig = procFig(fig)
figdf = index.queryMeta("""
WITH t AS (
SELECT
UNNEST(sum_topic_counts_vals) as topic_vals,
UNNEST(sum_topic_counts_inds) - 1 as topic_id, -- duckdb is 1 indexed
year(published::DATE) as year,
score
FROM doc
)
SELECT
topic_id,
year,
count(*) as n_posts,
avg(score) as avg_score,
avg((score > 10)::int) as p10,
avg((score > 100)::int) as p100,
FROM t
WHERE topic_vals > 5
GROUP BY topic_id, year
ORDER BY topic_id, year
""", paginate=True)
df.sample(5)| topic_id | year | n_posts | avg_score | p10 | p100 | |
|---|---|---|---|---|---|---|
| 1177 | 92 | 2013 | 10 | 6.600000 | 0.200000 | 0.000000 |
| 1872 | 150 | 2018 | 15 | 7.066667 | 0.133333 | 0.000000 |
| 662 | 52 | 2021 | 5 | 3.000000 | 0.000000 | 0.000000 |
| 975 | 77 | 2017 | 10 | 26.000000 | 0.200000 | 0.100000 |
| 1471 | 115 | 2025 | 1131 | 13.419982 | 0.129973 | 0.032714 |
tmp = topic_df.set_index("topic_id").to_dict()
df["topic"] = (df.topic_id).apply(tmp["short_title"].get)
df["topic_group"] = (df.topic_id).apply(tmp["topic_group_short_title"].get)
df = df.dropna().copy()
df.sample(5)| topic_id | year | n_posts | avg_score | p10 | p100 | topic | topic_group | |
|---|---|---|---|---|---|---|---|---|
| 129 | 10 | 2018 | 33 | 18.121212 | 0.181818 | 0.060606 | DIY Hardware IoT Projects | Projects and Personal Development |
| 53 | 5 | 2011 | 1 | 48.000000 | 1.000000 | 0.000000 | AI-Driven Personalization | Artificial Intelligence |
| 1817 | 146 | 2021 | 13 | 32.307692 | 0.307692 | 0.076923 | Wikipedia Article Tracking | Data and Analytics |
| 618 | 49 | 2018 | 8 | 5.875000 | 0.125000 | 0.000000 | Creative Computing Commands | Interactive Media and Games |
| 2053 | 167 | 2014 | 83 | 8.120482 | 0.168675 | 0.012048 | Crypto Commerce | Finance and Commerce |
We don’t want to overindex on topics that have only a few submissions per year but do extremely well. To add some smoothening, we add a simple prior that assumes 2/50 posts receive 100 points. This penalized topics that only have a few submissions.
df["P(score>100)"] = df.apply(lambda x: (x["p100"]*x["n_posts"]+ 2)/ (x["n_posts"]+50), axis=1)tmp = df.loc[df.year==2025]
tmp.sort_values("P(score>100)", ascending=False).head()[["topic", "P(score>100)"]]| topic | P(score>100) | |
|---|---|---|
| 136 | DIY Hardware IoT Projects | 0.093923 |
| 1031 | Open Source Projects | 0.087985 |
| 2132 | Error Handling and Debugging | 0.078652 |
| 1997 | Programming Language Interpreters | 0.077095 |
| 1458 | Life Narratives | 0.067568 |
df["title"] = "Show HN<br> Performance<br>2025"
fig = px.sunburst(df.loc[df.year==2025], path=["title", "topic_group", "topic"],
values="n_posts", color_continuous_scale="greens",
color="P(score>100)", height=600)
procFig(fig)df["title"] = "Show HN<br>Performance"
fig = px.treemap(df, path=["title", "year", "topic_group", "topic"],
values="n_posts", color_continuous_scale="greens",
color="P(score>100)", height=600, )
procFig(fig)It looks like Show HN really start performing amazingly well during this stretch, with a return to normalcy in 2025.
from sturdystats import Index
index = Index("Custom Analysis")
index.upload(df.to_dict("records"))
index.commit()
index.train()
# Ready to Explore
index.topicSearch()